LangGraph Rollout: Evolving VeRL's Multi-Turn Capabilities for Agent RL
After completing our multi-turn tokenization and masking refactoring, we eliminated a critical bottleneck that was preventing us from building a more consistent and flexible rollout system for our Agent RL research. This breakthrough enabled us to implement a LangGraph-based rollout for VeRL in just a few days, which we’ve already successfully deployed in our Agent RL experiments. In this article, I’ll share our journey from VeRL’s native multi-turn implementation to our new LangGraph-based solution, explaining both the motivations driving this evolution and the technical details of our implementation.
The Starting Point: VeRL’s Native Multi-Turn Approach
Our use case represents a typical agent RL setup: we have a comprehensive set of tools and handle a diverse range of user queries. Our objective is to train language models to intelligently select and utilize the appropriate tools to resolve user queries through multi-turn multi-step conversations.
Given the complexity of this end goal, we adopted a phased approach. We started with a multi-step single-turn scenario where:
- There’s only one user message in the conversation
- The model makes multiple tool calls across several steps
- The model provides a final answer incorporating all information gathered from the tools
This scenario is natively supported by VeRL’s multi-turn capabilities. Let’s examine the configuration required for such an experiment.
Configuration and Implementation
Using the GSM8K multi-turn example from VeRL’s repository as reference, we can see that the setup largely mirrors a standard VeRL configuration with three key additions:
1. Enable multi-turn rollout in the training config:
1
2
3
4
5
6
actor_rollout_ref:
rollout:
name: "sglang"
multi_turn:
enable: True
tool_config_path: /path/to/tool_config.yaml
Expand
2. Define tool schemas and class references:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
tools:
- class_name: "verl.tools.gsm8k_tool.Gsm8kTool"
config:
type: native
tool_schema:
type: "function"
function:
name: "calc_gsm8k_reward"
description: "A tool for calculating the reward of gsm8k. (1.0 if parsed answer is correct, 0.0 if parsed answer is incorrect or not correctly parsed)"
parameters:
type: "object"
properties:
answer:
type: "string"
description: "The model's answer to the GSM8K math problem, must be a digits"
required: ["answer"]
Expand
3. Implement tools following VeRL’s interface:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
class Gsm8kTool(BaseTool):
...
async def execute(self, instance_id: str, parameters: dict[str, Any], **kwargs) -> Tuple[str, float, dict]:
answer = parameters.get("answer", "")
if not isinstance(answer, str):
answer = str(answer)
if answer.startswith("#### "):
self._instance_dict[instance_id]["response"] = answer
else:
self._instance_dict[instance_id]["response"] = "#### " + answer
reward = await self.calc_reward(instance_id)
# penalty for non improved answer submission
tool_reward = 0.0 if reward > self._instance_dict[instance_id]["reward"] else -0.05
# update the reward
self._instance_dict[instance_id]["reward"] = reward
return f"Current parsed {answer=} {reward=}", tool_reward, {}
...
Expand
This native approach proved remarkably efficient — we had our experiments up and running within just two days. The elegance of this system stems from its simplicity: developers need to provide only three components:
- Training data (identical to single-turn LLM RL)
- A reward function (identical to single-turn LLM RL)
- Tool definitions and implementations
VeRL automatically handles all the low-level implementation details, freeing researchers to focus on their experiments.
Limitations of the Native Approach
After completing our initial exploration phase and beginning intensive experiments, we encountered two issues with VeRL’s native multi-turn implementation.
1. Redundancy in Tool Definition
The native approach requires defining each tool twice — once in the YAML configuration and once in the implementation. While manageable with a handful of tools during initial experiments, this duplication became increasingly burdensome as our tool ecosystem expanded and evolved.
Ideally, the tool schema could be automatically derived from the implementation itself, similar to how modern frameworks like Transformers and LangChain handle tool definitions through utility functions:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def multiply(a: int, b: int) -> int:
"""
Multiply two numbers.
Args:
a: The first number to multiply
b: The second number to multiply
Returns:
The product of a and b
"""
return a * b
from transformers.utils import get_json_schema
tool_schema = get_json_schema(multiply)
Expand
This automatically generates the complete schema:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
{
"type": "function",
"function": {
"name": "multiply",
"description": "Multiply two numbers.",
"parameters": {
"type": "object",
"properties": {
"a": {
"type": "integer",
"description": "The first number to multiply"
},
"b": {
"type": "integer",
"description": "The second number to multiply"
}
},
"required": ["a", "b"]
},
"return": {
"type": "integer",
"description": "The product of a and b"
}
}
}
Expand
2. Consistency Challenges
We also encountered two consistency issues:
Schema-Implementation Mismatch: With tool definitions split between YAML configuration and Python implementation, engineers occasionally updated one without synchronizing the other. This created discrepancies between tool descriptions and their actual functionality, leading to subtle bugs and unexpected behavior during training.
Production-Training Gap: VeRL’s custom BaseTool interface differs significantly from standard tool definition interfaces like those in LangGraph. This forced us to maintain two separate versions of each tool:
- Production tools integrated with LangGraph
- VeRL-compatible versions for training
For complex tools, maintaining logical consistency between these parallel implementations proved challenging.
Intermediate Solution: Automatic Tool Wrapping
To address these issues, I developed a solution that enables direct use of production tool implementations. The key was adding a helper method to VeRL’s BaseTool interface that automatically extracts schemas and creates VeRL-compatible instances from standard Python callables:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
class BaseTool:
@staticmethod
def from_callable(tool: Callable) -> "BaseTool":
"""Create a BaseTool instance from a callable python function."""
from transformers.utils import get_json_schema
instance = BaseTool({}, tool_schema=OpenAIFunctionToolSchema.parse_obj(get_json_schema(tool)))
tool_name = instance.tool_schema.function.name
logger = logging.getLogger(tool_name)
logger.setLevel(os.getenv("VERL_LOGGING_LEVEL", "WARN"))
async def execute(self, instance_id: str, parameters: dict[str, Any], **kwargs) -> Tuple[str, float, dict]:
try:
res = tool(**parameters)
if isinstance(res, dict | list):
res = json.dumps(res)
else:
res = str(res)
return res, 0.0, {}
except JSONDecodeError as e:
logger.error(f"JSONDecodeError in {tool_name}: {str(e)}. Tool Response: {res}")
return json.dumps({"error": f"Failed to invoke {tool_name}"}), 0.0, {}
except Exception as e:
logger.error(f"Error in {tool_name}: {str(e)}. Parameters: {parameters}")
return json.dumps({"error": f"Failed to invoke {tool_name}"}), 0.0, {}
async def release(self, instance_id: str, **kwargs) -> None:
if hasattr(tool, "__del__"):
tool.__del__()
instance.execute = types.MethodType(execute, instance)
instance.release = types.MethodType(release, instance)
return instance
Expand
This approach dramatically simplified our workflow. Now we could simply collect our production tools in a list and reference them directly in the training configuration:
1
2
3
4
5
6
7
8
9
def multiply(a: int, b: int) -> int:
...
def add(a: int, b: int) -> int:
...
...
tool_list = [multiply, add, minus, ...]
Expand
Then reference this list in the YAML configuration:
1
2
3
4
multi_turn:
enable: True
max_turns: 30
tool_list: custom.tools.tool_list
Expand
Since these tools were implemented as standard Python functions, we could also easily use LangChain’s tool decorator to make them fully compatible with the broader LangChain ecosystem, creating perfect alignment between training and production environments.
The Final Challenge: Evolving Beyond Simple Orchestration
While the automatic tool wrapping solution streamlined our workflow and served us well initially, our agent systems were rapidly evolving in sophistication and complexity. As we pushed the boundaries of agent RL research and deployed increasingly advanced systems, we began to encounter fundamental architectural limitations that demanded a more comprehensive solution.
Emerging Requirements for Advanced Agent Systems
Our research and production needs revealed three critical requirements that transcended what the existing approach could reasonably support:
1. Complex Orchestration Patterns
Our production systems had evolved to use sophisticated LangGraphs with advanced features that would be prohibitively difficult to replicate within VeRL’s native framework:
- Dynamic Branching Logic: Decision nodes that route execution based on intermediate results
- Backtracking Capabilities: Ability to revert to previous execution states when failures occur and explore alternative solution paths
- Tools Integration: Seamless connection with MCP servers and other specialized tools
Reimplementing these complex patterns within VeRL would not only require significant engineering effort but would also create a maintenance burden as production systems evolved.
Additionally, we encountered inconsistencies between LangChain and VeRL in how they handle tool arguments and errors, further highlighting the benefits of using a unified execution environment for both training and production.
2. True Multi-Turn Conversation Support
VeRL’s native multi-turn implementation was optimized for multi-step single-turn scenarios with a fundamental limitation: any assistant message without tool calls was treated as a conversation endpoint. This design assumption made it impossible to support genuine multi-turn dialogues where:
- Users or simulated users could ask follow-up questions
- The conversation could span multiple turns
To enable advanced agent scenarios, we needed a framework that could handle the full complexity of natural conversation patterns.
3. Fine-grained Configuration Control
Different stages of an agent workflow could benefit from different model configurations:
- Custom Chat Template Arguments: Some nodes might need reasoning enabled in chat templates while others should not
- Format Control: Certain interactions require structured output with specific formats while others need natural language responses
- Varied Sampling Parameters: Different steps in the workflow might require unique temperature, top-p, or other sampling parameters
The existing approach applied uniform settings across the entire interaction, which limited our ability to optimize performance for specific parts of the agent workflow.
Architectural Vision: Separation of Concerns
After carefully evaluating these requirements against our architectural constraints, I realized we needed to fundamentally rethink our approach. The core insight was a clear separation of concerns: VeRL’s rollout excels at efficient hardware management for model serving and actor weight updates, while specialized frameworks like LangGraph are already optimized for complex agent orchestration.
This insight led to a more sustainable and scalable architecture: allow VeRL to focus exclusively on its RL infrastructure strengths while delegating the complex orchestration logic to specialized frameworks like LangGraph. This clean separation benefits both VeRL maintainers and users — enabling more advanced agent research through battle-tested orchestration frameworks without unnecessarily complicating VeRL’s codebase.
LangGraph Integration: Bridging Production and Training
Based on this vision, we developed an elegant solution: directly integrate production LangGraphs into VeRL’s RL pipeline. This approach creates perfect alignment between training and deployment environments, allowing the exact same agent logic to run in both contexts.
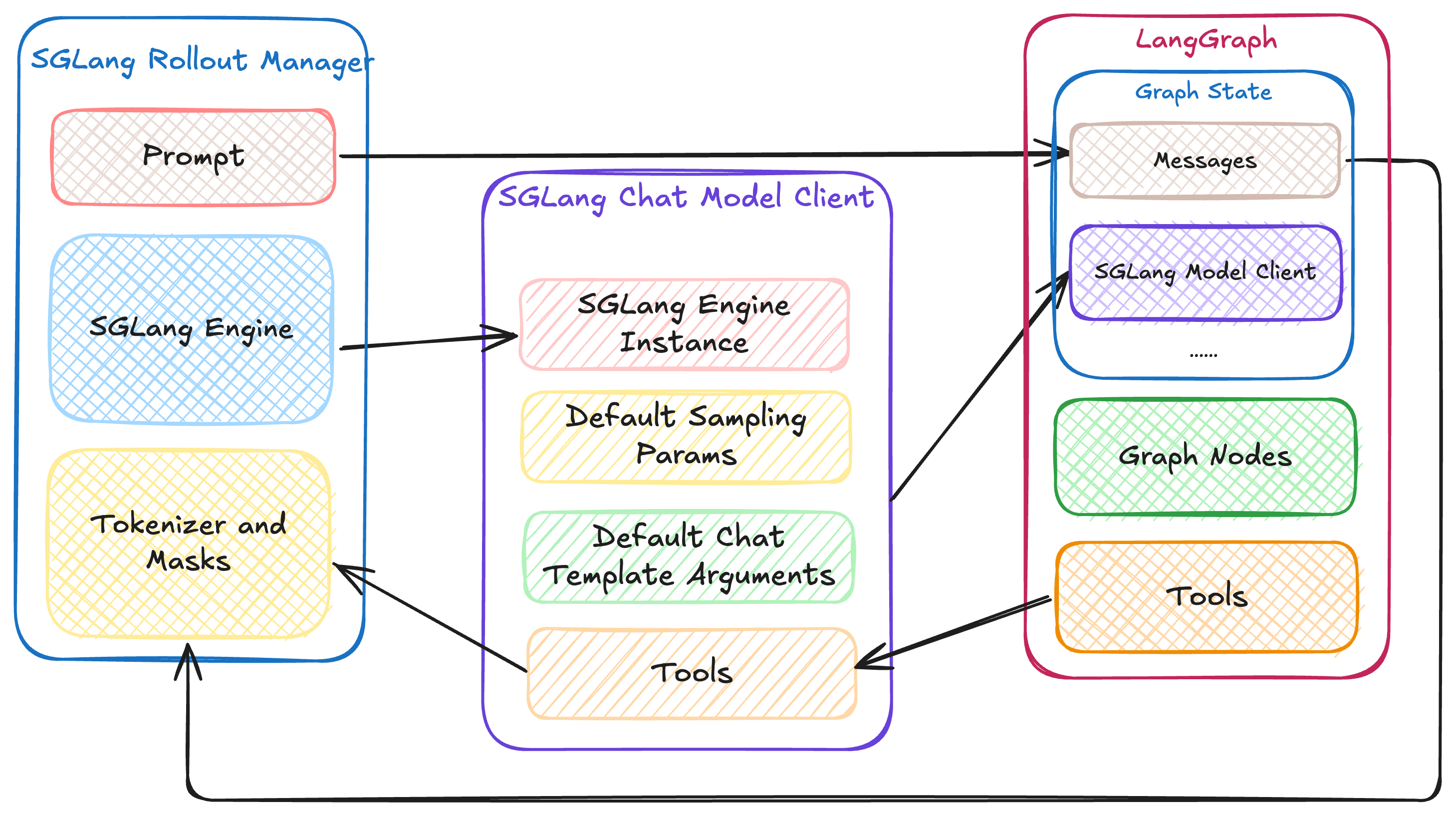
Architecture
We implemented a LangChain-compatible chat model client for VeRL’s SGLang rollout engine that serves as the bridge between VeRL and user-defined LangGraphs:
- Initialization: VeRL passes the initial messages and SGLang chat model client to the user’s graph when invoking it. The graph can leverage the model client to inference with the actor model.
- Execution: The graph orchestrates the conversation flow, making model queries through the client as needed
- Completion: Once the conversation is done, the system extracts the tools used during execution and retrieves the final message history from the graph state for tokenization and masking
Implementation Example: From Configuration to Execution
I’ve created a PR that implements this approach. Below is an example that demonstrates how to integrate your own LangGraph into the VeRL training pipeline:
Configuration Setup
The rollout configuration is straightforward, requiring only a path to your graph implementation and any graph-specific configuration parameters:
1
2
3
4
5
6
7
actor_rollout_ref:
rollout:
multi_turn:
chat_template_kwargs: {"enable_thinking": False}
langgraph:
path: /path/to/graph.py
graph_config: {"recursion_limit": 100}
Expand
Graph Implementation
In your graph script, you can implement any LangGraph pattern while ensuring it accepts and utilizes the VeRL-provided actor model:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
from typing import Annotated, Optional
from langchain_core.messages import AnyMessage
from langchain_core.runnables import RunnableSerializable
from langchain_core.tools import tool
from langgraph.graph import add_messages, StateGraph, START, END
from langgraph.prebuilt import ToolNode
from pydantic import BaseModel
class GraphState(BaseModel):
# The actor model and message history are automatically injected by the SGLang rollout manager during RL training
# In production environments, these can be assigned using a standard LangChain model client
actor: RunnableSerializable # VeRL provides a SGLangChatModel compatible with LangChain's interfaces
messages: Annotated[list[AnyMessage], add_messages]
max_turn: int = 30
turn_count: int = 0
next: Optional[str] = None
# 1. Define tools
@tool
def tool() -> str:
...
# 2. Define tool node
tools = [...]
tool_node = ToolNode(tools)
# 3. bind tools to the model
def bind_tools(state: GraphState) -> dict:
return {"actor": state.actor.bind_tools(tools)}
# 4. define agent node
def agent(state: GraphState) -> dict:
if state.turn_count >= state.max_turn:
return {"next": END}
# chat_template_kwargs and sampling_params can be different for different model invocation
response = state.actor.invoke(
state.messages,
chat_template_kwargs={"enable_thinking": False},
sampling_params={"temperature": 1.0}
)
if response.tool_calls and response.response_metadata["finish_reason"]["type"] == "stop":
return {"next": "tools", "messages": response, "turn_count": state.turn_count + 1}
elif response.content:
return {"next": END, "messages": response, "turn_count": state.turn_count + 1}
return {"next": END, "turn_count": state.turn_count + 1}
# 5. Build the graph
builder = StateGraph(GraphState)
builder.add_node("bind_tools", bind_tools)
builder.add_node("agent", agent)
builder.add_node("tools", tool_node)
builder.add_edge(START, "bind_tools")
builder.add_edge("bind_tools", "agent")
builder.add_conditional_edges("agent", lambda x: x.next)
builder.add_edge("tools", "agent")
graph = builder.compile()
Expand
This example demonstrates a setup equivalent to the current multi-step rollout, but the pattern can be extended to build much more sophisticated agent systems. And this approach is not limited to LangGraph either—for other agent frameworks, implementing a similar dedicated client for the rollout engine would enable integration with those frameworks as well. This allows us to take full advantage of the different agent orchestration systems and the tools/utilities these frameworks already support.
Next Steps
The LangGraph integration implementation is currently in prototype stage. Although we’ve already deployed it successfully in production experiments with promising results, I plan to engage with the broader VeRL community to ensure this design aligns with current and planned features for multi-turn rollout. The feedback from this process will help refine and potentially extend the implementation further.
Feel free to try it out yourself! Any feedback, issues, or enhancement suggestions are welcome on the PR. I’m particularly interested in hearing about how this approach works with more complex agent architectures and workflows.