Efficient Forward Pass for Agent RL: Solving Multi-Turn Context Consistency (Part 1)
After implementing correct and scalable tokenization and masking1 for multi-turn rollout, there remains a critical challenge to achieve full consistency between training and inference: the context discrepancy problem.
The Training-Inference Context Mismatch
In my previous post, I briefly mentioned this issue. Now, let’s dive deep into why it matters and how to solve it efficiently.
Consider a typical multi-turn conversation where each assistant message contains both reasoning (think) and response components:
Human Query 1 → Assistant Message 1 (reasoning + response) → Human Query 2 → Assistant Message 2 (reasoning + response) → …
During inference, reasoning models strip out the reasoning content from previous turns, keeping only the responses. The figure below illustrates how each turn’s context changes:
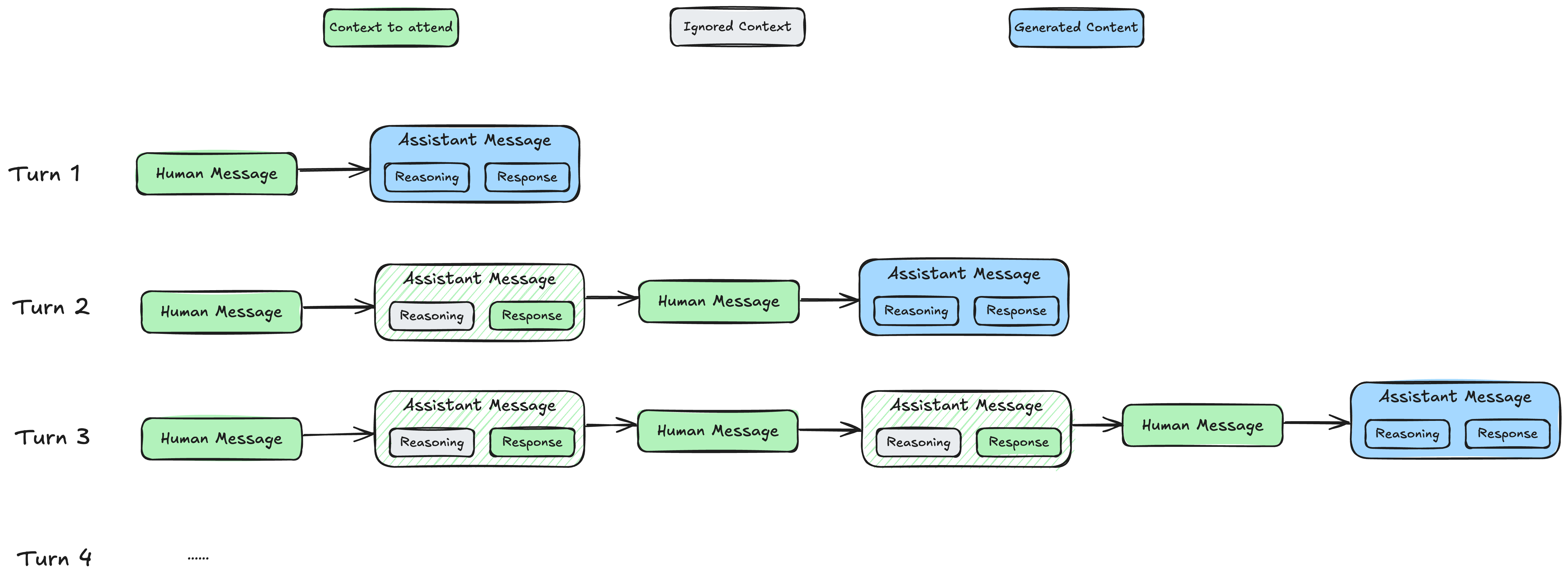
However, during training, we must preserve the reasoning content from each assistant message to enable the model to learn reasoning capabilities. For each sample, training frameworks typically pack all turns within that sample together and perform a single forward pass for loss or log probability calculation, which means the computation includes the complete reasoning content for all assistant messages:
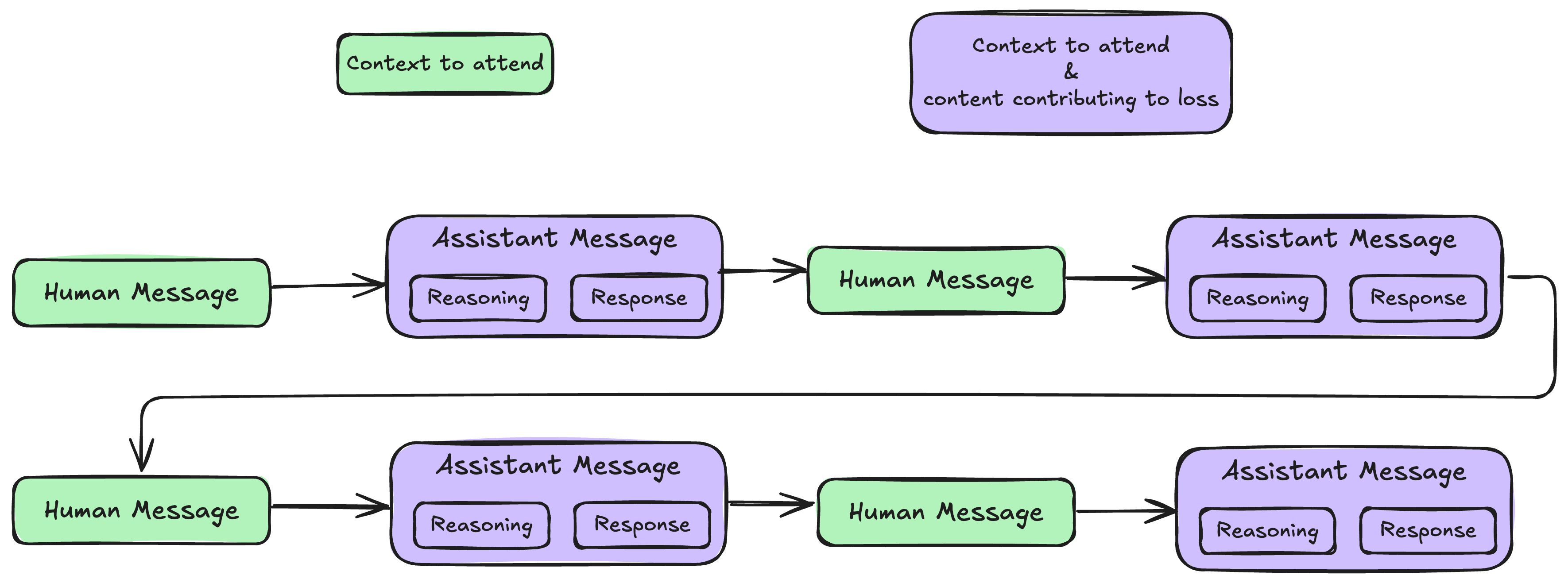
This creates a fundamental problem: models are trained on contexts they never see during inference. In this post, I’ll explore three approaches to bridge this gap, with detailed implementations and performance analysis.
Approaches to Bridge the Training-Inference Gap
To evaluate different solutions for VeRL, I built prototypes using Qwen3-4B and analyzed their correctness, performance, and practicality. Let’s examine each approach in detail.
Base Solution: Turn-by-Turn Forward Passes
The most straightforward approach mimics inference behavior exactly: process each turn individually with separate forward passes.
Why Standard Multi-Turn Training Works
Before diving into the solution, let’s understand why typical multi-turn training can pack all turns into a single forward pass. The key insight is content immutability: once tokens are generated in a turn, they remain unchanged when included as context for future turns.
This immutability enables an important optimization:
- Training: Calculate loss for all turns in one forward pass
- Inference: Run separate forward passes per turn (inherent to autoregressive generation)
These produce identical results because the tokens from earlier turns don’t change. The model sees the exact same sequences whether processed together or separately.
Why Reasoning Models Break This Assumption
Reasoning models violate content immutability. When an assistant message becomes part of the chat history, the model’s chat template removes the reasoning tokens:
- Training sees:
Human 1 → Assistant 1 (reasoning + response) → Human 2 → Assistant 2 (reasoning + response) - Inference sees:
- Turn 2:
Human 1 → Assistant 1 (response only) → Human 2 → Assistant 2 (reasoning + response) - Turn 3:
Human 1 → Assistant 1 (response only) → Human 2 → Assistant 2 (response only) → Human 3 → Assistant 3 (reasoning + response)
- Turn 2:
The model trains on contexts it will never encounter during inference, creating a distribution mismatch.
The Turn-by-Turn Approach
This solution restores correctness by mimicking inference behavior during training:
- Process each turn individually with separate forward passes
- For each turn, apply the same context modifications (reasoning removal) used during inference
- Calculate loss only on the current turn’s assistant response
- Aggregate losses from all turns
The following diagram illustrates this turn-by-turn processing:
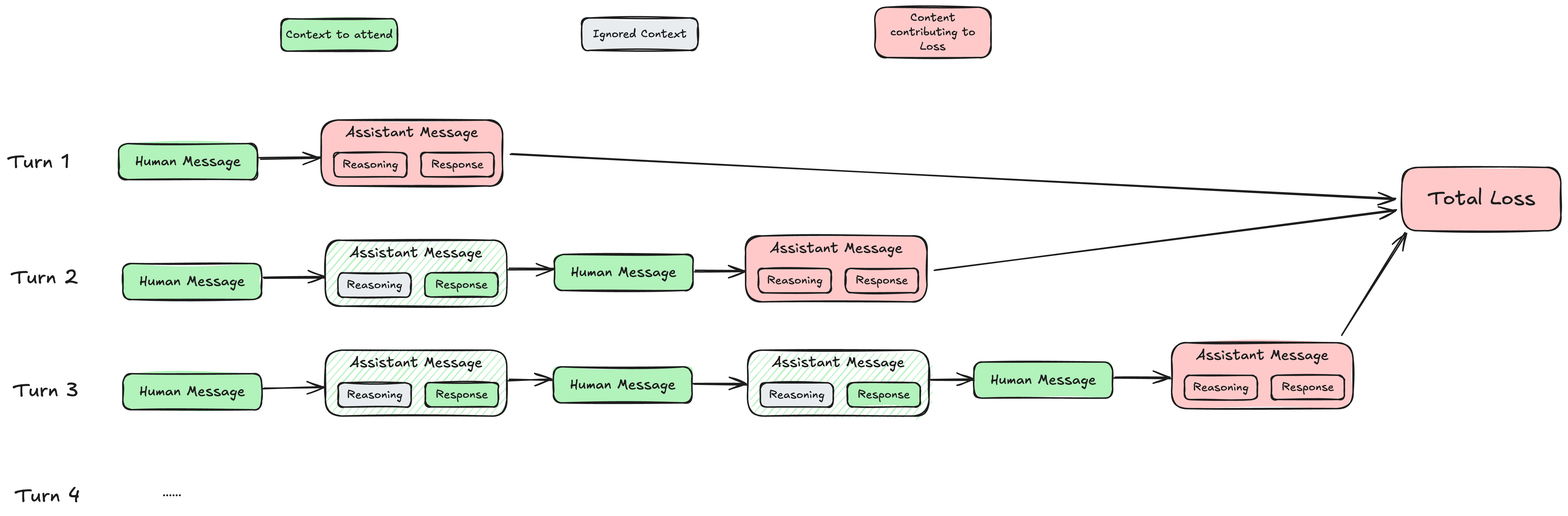
This solution serves as our correctness baseline. While computationally expensive, it provides a reference point to validate the outputs of more optimized approaches.
Reference Implementation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Test conversation with reasoning in assistant messages
messages = [
{"role": "user", "content": "What is 15 + 27?"},
{"role": "assistant", "content": "<think>I need to add 15 and 27. 15 + 27 = 42.</think>The answer is 42."},
{"role": "user", "content": "Now multiply that by 3."},
{"role": "assistant", "content": "<think>The previous result was 42. 42 × 3 = 126.</think>42 times 3 equals 126."},
{"role": "user", "content": "What's half of that?"},
{"role": "assistant", "content": "<think>Half of 126 is 126 ÷ 2 = 63.</think>Half of 126 is 63."}
]
# Same messages without reasoning (for context building)
messages_wo_reasoning = [
{"role": "user", "content": "What is 15 + 27?"},
{"role": "assistant", "content": "The answer is 42."},
{"role": "user", "content": "Now multiply that by 3."},
{"role": "assistant", "content": "42 times 3 equals 126."},
{"role": "user", "content": "What's half of that?"},
{"role": "assistant", "content": "Half of 126 is 63."}
]
assistant_message_indices = [1, 3, 5]
# Initialize model
model_id = "Qwen/Qwen3-4B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="cuda:0")
# Process each turn separately
all_logits = []
for idx in assistant_message_indices:
prompt = tokenizer.apply_chat_template(
messages[:idx], add_generation_prompt=True, tokenize=True
)
# Full conversation including current assistant response
input_ids = tokenizer.apply_chat_template(
messages[:idx+1],
add_generation_prompt=False,
return_tensors="pt",
tokenize=True
).to(model.device)
# Forward pass and extract assistant response logits
all_logits.append(model(input_ids=input_ids).logits[:, len(prompt):, :])
final_logits_base = torch.cat(all_logits, dim=1)
Expand
Measuring Numerical Differences
Since optimizations involve different computation paths and CUDA kernels, numerical differences are inevitable. I use multiple metrics to quantify these differences:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
def compare_logits(logits1, logits2):
"""Compare two logit tensors using multiple metrics."""
flat1 = logits1.view(-1, logits1.size(-1))
flat2 = logits2.view(-1, logits2.size(-1))
rmse = (flat1 - flat2).pow(2).mean().sqrt().item()
print(f"RMSE Distance: {rmse}")
from torch.nn.functional import softmax, kl_div
# KL divergence: KL(P||Q) where P is the reference distribution
# Computing KL(logits2||logits1) - how much information is lost when using logits1 to approximate logits2
kl = kl_div(softmax(logits1, dim=-1).log(), softmax(logits2, dim=-1), reduction='batchmean').item()
print(f"KL divergence (logits||expected): {kl}")
# Also compute the reverse KL for completeness
kl_reverse = kl_div(softmax(logits2, dim=-1).log(), softmax(logits1, dim=-1), reduction='batchmean').item()
print(f"KL divergence (expected||logits): {kl_reverse}")
# Symmetric KL divergence (average of both directions)
print(f"Symmetric KL divergence: {(kl + kl_reverse) / 2}")
def topk_overlap(a, b, k):
ta = torch.topk(a, k, dim=-1).indices
tb = torch.topk(b, k, dim=-1).indices
return (ta.unsqueeze(-1) == tb.unsqueeze(-2)).any(dim=-1).float().mean().item()
print(f"Top-1 overlap: {topk_overlap(logits1, logits2, 1) * 100:.2f}%")
print(f"Top-8 overlap: {topk_overlap(logits1, logits2, 8) * 100:.2f}%")
try:
torch.testing.assert_close(logits2, logits1, rtol=1e-1, atol=1e-2)
except Exception as e:
print(e)
Expand
While this guarantees training-inference consistency, it comes with significant costs:
- Computational overhead: Redundant processing of shared chat history across turns
- Implementation complexity: Requires a different training loop pattern compared to standard single-turn or packed multi-turn training
Optimized Solution 1: KV Cache Acceleration
The base solution mirrors inference behavior, so we can apply the same optimization used during inference: KV caching. This maintains correctness while dramatically reducing computational redundancy.
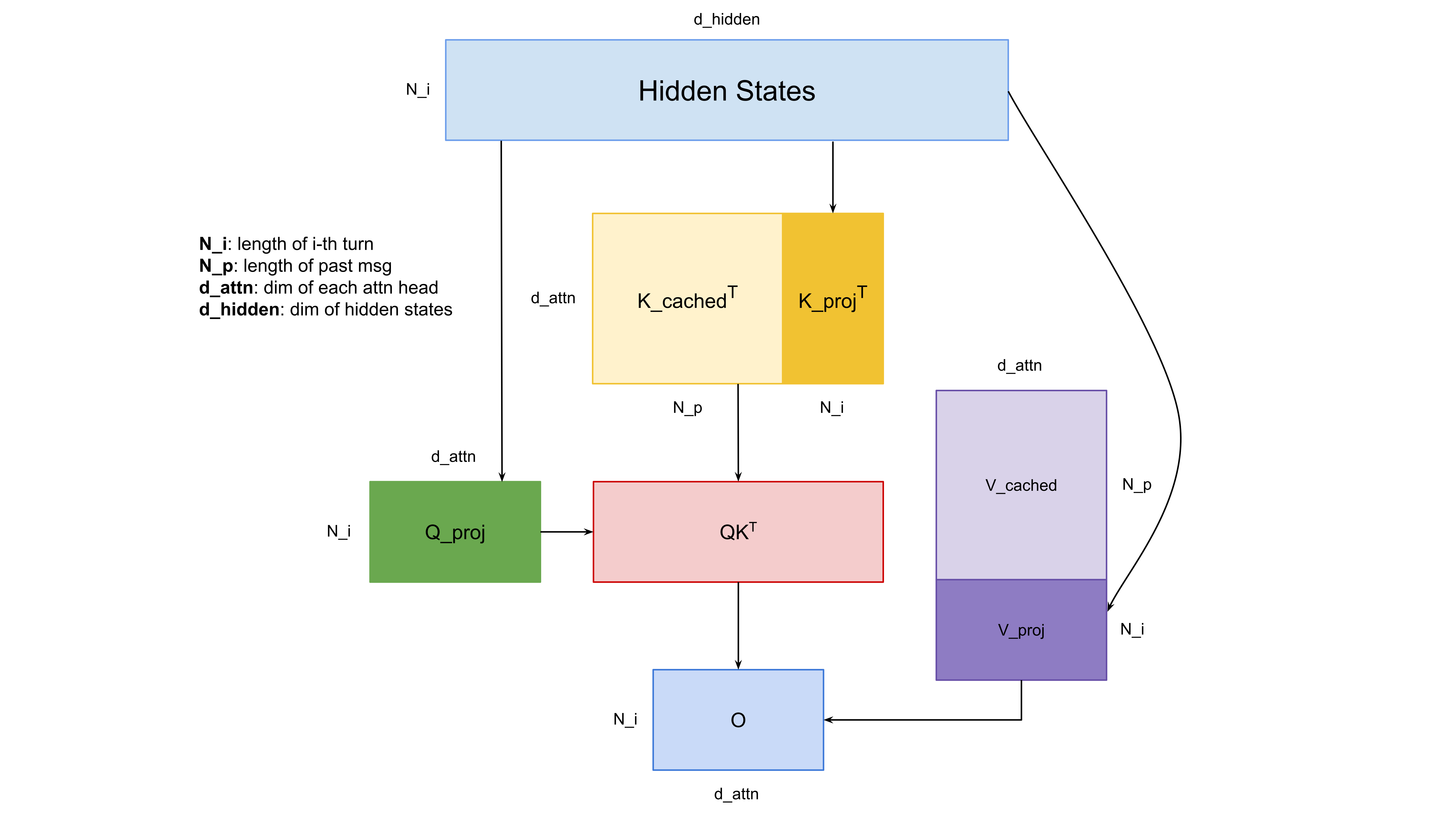
The KV Cache Strategy
HuggingFace models provide built-in KV cache support2, allowing us to cache key-value projections and reuse them across turns:
- Process with reasoning: Run forward pass for assistant message with reasoning content
- Cache KV states: Save the key-value projections from all attention layers
- Crop cache: Remove KV entries for the assistant’s response, keeping only the prompt
- Rebuild without reasoning: Process the assistant message again without reasoning to update cache
- Continue: Use updated cache for subsequent turns
This optimization reduces computational complexity from O(n²) to O(n) for n turns, as shown below:
Implementation and Validation
Using the same conversation setup from the base solution, here’s the optimized KV cache version:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
from transformers.cache_utils import OffloadedCache
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="cuda:1")
# Initialize KV cache
kv_cache = OffloadedCache()
all_logits = []
for idx in assistant_message_indices:
prompt = tokenizer.apply_chat_template(messages[:idx], add_generation_prompt=True, tokenize=True)
input_ids_w_think = tokenizer.apply_chat_template(
messages[:idx+1],
add_generation_prompt=False,
return_tensors="pt",
tokenize=True
).to(model.device)
# Forward pass using cached KV states
all_logits.append(
model(
input_ids=input_ids_w_think[:, kv_cache.get_seq_length():],
past_key_values=kv_cache
).logits[:, len(prompt) - input_ids_w_think.shape[-1]:, :] # Extract logits for current assistant message
)
# Remove assistant response from KV cache
kv_cache.crop(len(prompt))
# Rebuild cache with reasoning-free version
# Note: Qwen3 adds empty <think> tags for non-reasoning messages
inputs_wo_think = tokenizer.apply_chat_template(
messages_wo_reasoning[:idx+1],
add_generation_prompt=False,
tokenize=False
).replace("<think>\n\n</think>\n\n", '') # Remove empty tags
input_ids_wo_think = tokenizer.encode(inputs_wo_think, return_tensors="pt").to(model.device)
# Update KV cache with reasoning-free context
model(input_ids=input_ids_wo_think[:, kv_cache.get_seq_length():], past_key_values=kv_cache)
final_logits_kv_cache = torch.cat(all_logits, dim=1)
Expand
This optimization reduces the computational complexity from O(n²) to O(n) for processing n turns, making it much more efficient while maintaining exact consistency with inference behavior.
Numerical Accuracy Analysis
When comparing the KV cache optimization against the reference implementation, I observe small numerical differences:
1
2
3
4
5
6
7
8
9
10
11
RMSE Distance: 0.0791015625
KL divergence (logits||expected): 0.042236328125
KL divergence (expected||logits): 0.033203125
Symmetric KL divergence: 0.0377197265625
Top-1 overlap: 99.10%
Top-8 overlap: 99.66%
Tensor-likes are not close!
Mismatched elements: 1508533 / 16864896 (8.9%)
Greatest absolute difference: 0.90625 at index (0, 54, 4969) (up to 0.01 allowed)
Greatest relative difference: 610304.0 at index (0, 76, 52622) (up to 0.1 allowed)
Expand
These differences arise from different CUDA kernel dispatch patterns:
- Linear Layer Kernels: When computing Q, K, V projections, the KV cache version processes only new tokens since previously computed projections are cached. This difference in sequence length causes PyTorch to dispatch different GEMM kernels:
- Base solution → Segmented K GEMM kernel
- KV cache → SplitK GEMM kernel
The SplitK kernel is chosen for shorter sequences because when the M dimension (sequence length: 37 tokens in this example) is small relative to the K dimension (hidden dimension: 2560 for Qwen3-4B), it’s more efficient to split the reduction work across multiple thread blocks. Longer sequences with larger M dimensions benefit from the segmented approach instead.
- Attention Kernels: Qwen3 uses PyTorch’s SDPA attention implementation3 by default, which automatically selects the most optimal backend among Flash Attention 2, xFormers, and PyTorch’s native C++ implementation based on hardware and input characteristics. HuggingFace models are configured to enable Flash Attention 2 as the SDPA backend when possible. In this case, both base and KV cache solutions routed to Flash Attention 2, but the different query and key-value sequence lengths triggered different kernels within Flash Attention:
- Base solution →
flash_fwd_kernel(standard Flash Attention kernel) - KV cache →
flash_fwd_splitkv_kernel(Flash Attention’s kernel variant for handling different Q and KV sequence lengths, which occurs in KV caching scenarios)
- Base solution →
These numerical differences show the following characteristics:
- 99%+ top-1 token prediction overlap
- Low KL divergence indicating similar probability distributions
- The differences can be eliminated by forcing the same kernel paths, confirming they’re purely computational artifacts rather than algorithmic issues
Optimized Solution 2: Custom 2D Attention Mask
Another approach leverages customized 2D attention masks to selectively control which tokens can attend to each other, enabling single-pass training while maintaining inference-like context visibility.
Understanding Attention Masks
When tokenizing text with HuggingFace tokenizers, the returned attention mask is a 1D binary mask indicating valid tokens (1) versus padding (0). However, this is not the mask used in actual attention computation.
The attention mechanism uses a 2D mask of shape [seq_len_q, seq_len_k] that specifies which query positions can attend to which key positions. For causal language models, the is_causal=True flag generates a lower-triangular mask, ensuring each token only attends to previous tokens and itself:
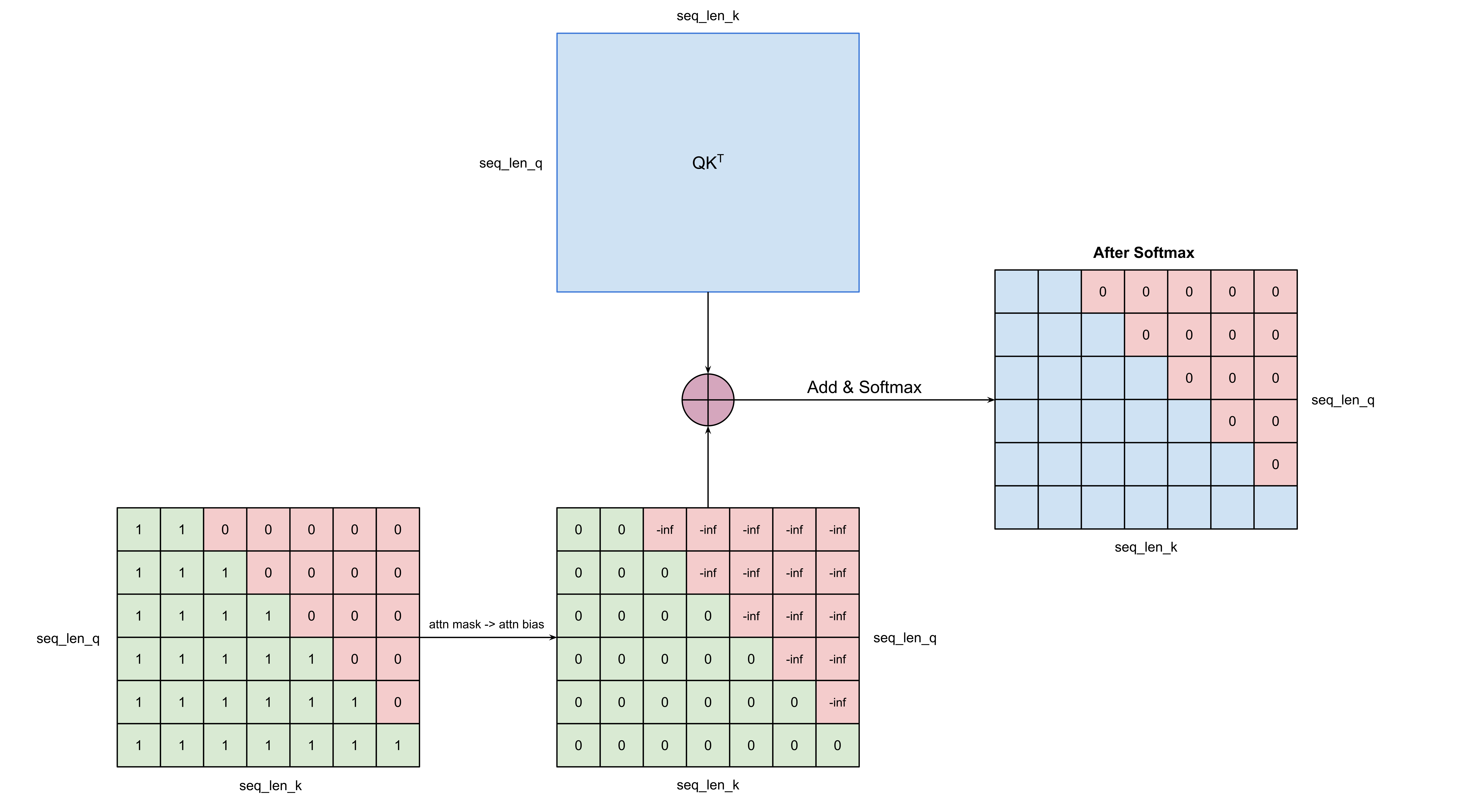
The mask values are converted to attention biases by replacing:
True/1(can attend) → 0False/0(cannot attend) → -∞
After adding this bias to the QK dot product and applying softmax, ignored positions become 0, effectively removing their contribution.
Duplicating Messages with Custom Masks
By crafting a custom 2D attention mask, we can make assistant messages attend only to their own reasoning content while ignoring reasoning from previous assistant messages — all within a single forward pass. This approach requires:
- Duplicate Assistant Messages: Include each assistant message twice in the input sequence:
- First copy: Without reasoning (for context)
- Second copy: With reasoning (for loss calculation)
- Custom Attention Patterns: Design the mask so that:
- All tokens attend to non-reasoning versions of previous assistant messages
- Current assistant tokens attend to their own reasoning content
- Other messages follow standard causal attention
- Adjusted Position IDs: Since we have duplicate content, position IDs no longer monotonically increase. Each copy of the same message starts from the same position id to maintain positional consistency.
The following visualization shows how this works at the message level:
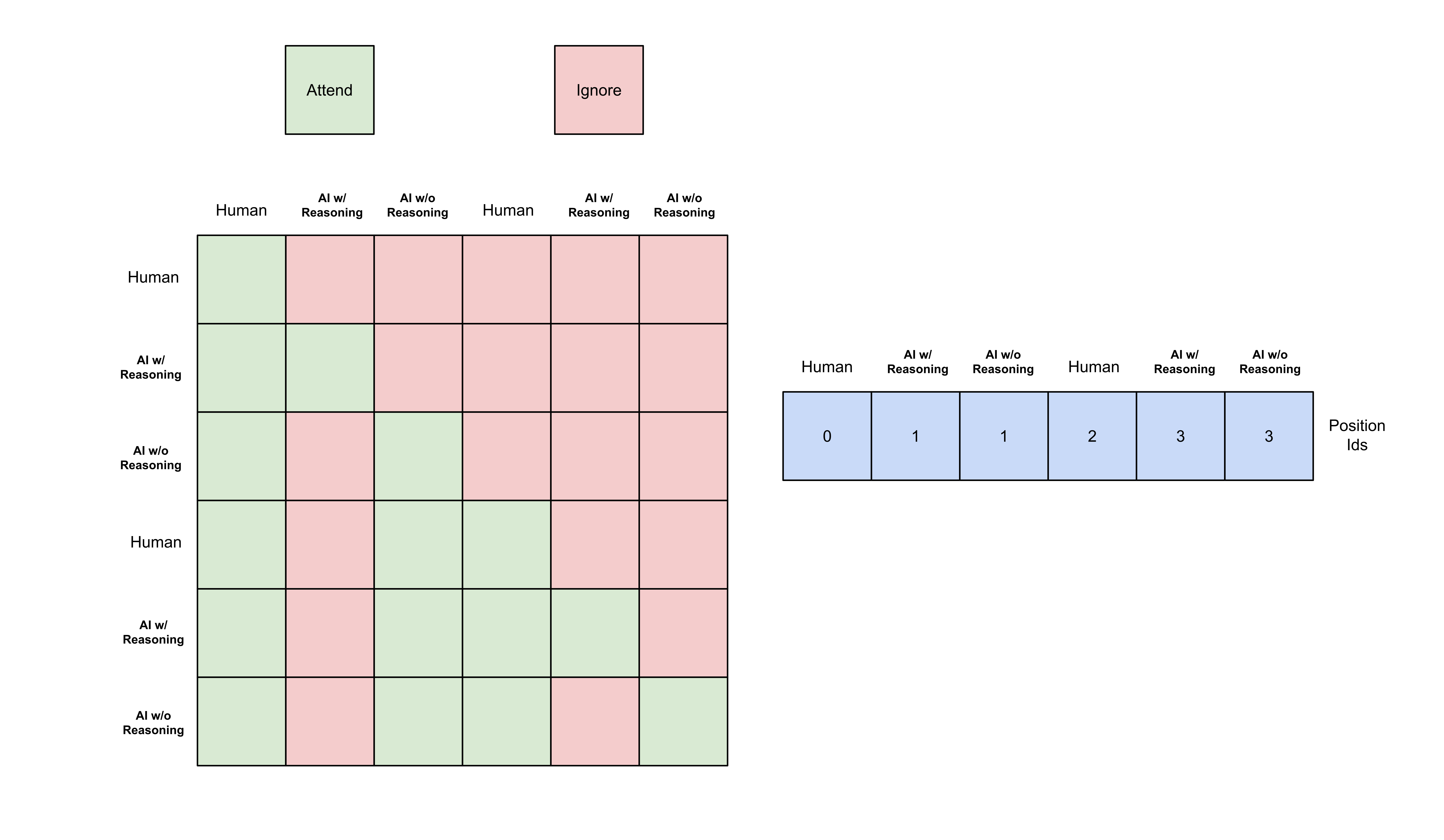
Red cells block attention to previous reasoning content while green cells allow normal attention flow.
Attention Backend Support
Different attention implementations have varying support for custom masks:
Flash Attention 2 - No custom mask support:
1
2
3
4
5
6
7
8
9
10
11
12
# Flash Attention only supports boolean causal flag, not custom masks (applies to both flash_attn_func and flash_attn_varlen_func)
flash_attn.flash_attn_func(
q, k, v,
dropout_p=0.0,
softmax_scale=None,
causal=False, # Boolean only - no custom masks
window_size=(-1, -1),
softcap=0.0,
alibi_slopes=None,
deterministic=False,
return_attn_probs=False,
)
Expand
PyTorch SDPA Attention - Limited custom mask support:
1
2
3
4
5
6
7
8
9
# SDPA accepts custom attention masks
torch.nn.functional.scaled_dot_product_attention(
query, key, value,
attn_mask=custom_mask, # Custom mask supported
dropout_p=0.0,
is_causal=False,
scale=None,
enable_gqa=False
)
Expand
However, passing a custom attn_mask prevents SDPA from using the Flash Attention backend. It falls back to either:
- xFormers: Limited experimental support for GQA (Group Query Attention)
- PyTorch C++ Attention Implementation: Slower and more memory-intensive
For models using GQA (like Qwen3), this often means falling back to the native implementation, negating performance benefits.
PyTorch FlexAttention4 - Flexible mask and scoring support:
1
2
3
4
5
6
7
8
9
10
# Flex Attention provides flexible mask and scoring options
torch.nn.attention.flex_attention.flex_attention(
query, key, value,
score_mod=custom_score_function, # Custom attention score bias
block_mask=custom_block_mask, # Custom attention patterns
scale=None,
enable_gqa=False,
return_lse=False,
kernel_options=None
)
Expand
FlexAttention not only supports arbitrary attention patterns but can also leverage sparsity in the attention mask for performance improvements. By analyzing which blocks need computation, it can skip unnecessary operations entirely.
Given these constraints, I evaluated both SDPA (with its limitations) and Flex Attention for implementing the custom 2D mask approach.
Implementation and Validation
Shared Input Preparation
Both SDPA and FlexAttention implementations share the same input preparation logic for constructing token IDs, position IDs, and attention masks:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
# Initialize tracking variables
current_turn_start = 0
assistant_tokens_offset = 0
all_token_ids = []
all_position_ids = []
# Track boundaries for mask construction and logits extraction
# Each tuple: (start_idx_with_reasoning, start_idx_without_reasoning)
assistant_message_boundaries = []
# Process each assistant turn
for turn_idx in assistant_message_indices:
# Tokenize prompt (everything before current assistant message)
prompt_tokens = tokenizer.apply_chat_template(
messages[:turn_idx],
add_generation_prompt=True,
tokenize=True
)
# Tokenize full conversation including current assistant (with reasoning)
tokens_with_reasoning = tokenizer.apply_chat_template(
messages[:turn_idx+1],
add_generation_prompt=False,
return_tensors="pt",
tokenize=True
)
# Tokenize conversation with reasoning removed
conv_without_reasoning = tokenizer.apply_chat_template(
messages_wo_reasoning[:turn_idx+1],
add_generation_prompt=False,
tokenize=False
).replace("<think>\n\n</think>\n\n", '') # Remove empty think tags
tokens_without_reasoning = tokenizer.encode(conv_without_reasoning, return_tensors="pt")
# Concatenate: [previous_tokens][assistant_with_reasoning][assistant_without_reasoning]
turn_tokens = torch.cat([
tokens_with_reasoning[:, current_turn_start:], # New tokens from this turn
tokens_without_reasoning[:, len(prompt_tokens):] # Assistant without reasoning
], dim=1)
all_token_ids.append(turn_tokens)
# Generate position IDs (duplicate positions for duplicate content)
turn_position_ids = torch.cat([
torch.arange(current_turn_start, tokens_with_reasoning.shape[-1], dtype=torch.long),
torch.arange(len(prompt_tokens), tokens_without_reasoning.shape[-1], dtype=torch.long)
]).unsqueeze(0)
all_position_ids.append(turn_position_ids)
# Track boundaries for attention mask and logit extraction
reasoning_start = assistant_tokens_offset + len(prompt_tokens)
no_reasoning_start = assistant_tokens_offset + tokens_with_reasoning.shape[-1]
assistant_message_boundaries.append((reasoning_start, no_reasoning_start))
# Update tracking variables
current_turn_start = tokens_without_reasoning.shape[-1]
assistant_tokens_offset += tokens_with_reasoning.shape[-1] - len(prompt_tokens)
# Combine all inputs
input_ids = torch.cat(all_token_ids, dim=1)
position_ids = torch.cat(all_position_ids, dim=1)
# Build custom 2D attention mask
# Shape: [batch_size, num_heads=1, seq_length, seq_length]
seq_length = input_ids.shape[1]
attention_mask = torch.ones(
input_ids.shape[0], 1, seq_length, seq_length,
dtype=torch.bool
)
# Apply masking rules: block attention from future tokens to past reasoning content
for reasoning_start, no_reasoning_start in assistant_message_boundaries:
attention_mask[:, :, no_reasoning_start:, reasoning_start:no_reasoning_start] = False
# Apply causal mask (lower triangular)
attention_mask = attention_mask.tril(diagonal=0)
Expand
SDPA Implementation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# Qwen3 uses SDPA attention by default
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="cuda:2"
)
# Forward pass with custom attention mask
all_logits = model(
input_ids=input_ids.to(model.device),
attention_mask=attention_mask.to(model.device),
position_ids=position_ids.to(model.device)
).logits
# Extract logits only for assistant messages with reasoning
assistant_logits_list = [
all_logits[:, reasoning_start:no_reasoning_start, :]
for reasoning_start, no_reasoning_start in assistant_message_boundaries
]
final_logits_sdpa_custom_mask = torch.cat(assistant_logits_list, dim=1)
Expand
Numerical Accuracy Analysis
1
2
3
4
5
6
7
8
9
10
11
RMSE Distance: 0.0791015625
KL divergence (logits||expected): 0.058837890625
KL divergence (expected||logits): 0.0257568359375
Symmetric KL divergence: 0.04229736328125
Top-1 overlap: 98.20%
Top-8 overlap: 99.10%
Tensor-likes are not close!
Mismatched elements: 2035728 / 16864896 (12.1%)
Greatest absolute difference: 0.921875 at index (0, 89, 59151) (up to 0.01 allowed)
Greatest relative difference: 1384448.0 at index (0, 76, 52622) (up to 0.1 allowed)
Expand
The numerical differences are slightly higher than the KV cache approach. The linear layers use the same SegmentK GEMM kernel as the base implementation due to the longer sequence length. However, SDPA falls back to PyTorch’s native C++ attention implementation instead of Flash Attention 2 when using custom attention masks and GQA, which likely contributes to the larger numerical discrepancies.
FlexAttention Implementation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
from torch.nn.attention.flex_attention import create_block_mask
# Load model with FlexAttention backend
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
attn_implementation="flex_attention",
device_map="cuda:3"
)
# Convert attention mask to FlexAttention's block mask format
# Extract the head-shared mask (all heads use the same pattern)
head_shared_mask = attention_mask[:, 0, :, :].to(model.device)
# Define mask modification function for FlexAttention
def mask_mod(b, h, q_idx, kv_idx):
return head_shared_mask[b, q_idx, kv_idx]
# Create block mask optimized for sparse attention patterns
block_mask = create_block_mask(
mask_mod,
B=input_ids.shape[0],
H=None, # Broadcast across all heads
Q_LEN=seq_length,
KV_LEN=seq_length,
device=model.device
)
# Forward pass with FlexAttention block mask
all_logits = model(
input_ids=input_ids.to(model.device),
attention_mask=block_mask,
position_ids=position_ids.to(model.device)
).logits
# Extract logits only for assistant messages with reasoning
assistant_logits_list = [
all_logits[:, reasoning_start:no_reasoning_start, :]
for reasoning_start, no_reasoning_start in assistant_message_boundaries
]
final_logits_flex_custom_mask = torch.cat(assistant_logits_list, dim=1)
Expand
Numerical Accuracy Analysis
1
2
3
4
5
6
7
8
9
10
11
RMSE Distance: 0.08740234375
KL divergence (logits||expected): 0.0966796875
KL divergence (expected||logits): 0.08837890625
Symmetric KL divergence: 0.092529296875
Top-1 overlap: 99.10%
Top-8 overlap: 99.21%
Tensor-likes are not close!
Mismatched elements: 2237592 / 16864896 (13.3%)
Greatest absolute difference: 1.0 at index (0, 89, 59151) (up to 0.01 allowed)
Greatest relative difference: 720896.0 at index (0, 0, 24300) (up to 0.1 allowed)
Expand
The numerical differences are comparable to the SDPA implementation. FlexAttention uses entirely different Triton-based kernels for both the attention computation and user-provided functions, which explains the similar magnitude of differences from the base implementation.
Comparison with VeRL’s Current Implementation
To understand the importance of these solutions, I compared them against VeRL’s current implementation, which includes all reasoning content during training (creating the context mismatch problem):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# VeRL's current approach: pack all turns with full reasoning
all_tokens = []
message_boundaries = []
cur_seq_len = 0
for idx in assistant_message_indices:
# Get prompt for current turn
prompt = tokenizer.apply_chat_template(
messages[idx-1:idx],
add_generation_prompt=True,
tokenize=True
)
# Get full turn including assistant response
input_ids = tokenizer.apply_chat_template(
messages[idx-1:idx+1],
add_generation_prompt=False,
return_tensors="pt",
tokenize=True
).to(model.device)
all_tokens.append(input_ids)
message_boundaries.append((cur_seq_len + len(prompt), cur_seq_len + input_ids.shape[-1]))
cur_seq_len += input_ids.shape[-1]
# Single forward pass with all reasoning visible
logits = model(input_ids=torch.cat(all_tokens, dim=1).to(model.device)).logits
final_logits_verl = torch.cat([
logits[:, ai_start:next_turn_start, :]
for ai_start, next_turn_start in message_boundaries
], dim=1)
Expand
The numerical differences are dramatically larger:
1
2
3
4
5
6
7
8
9
10
11
RMSE Distance: 2.171875
KL divergence (logits||expected): 22.875
KL divergence (expected||logits): 31.5
Symmetric KL divergence: 27.1875
Top-1 overlap: 91.89%
Top-8 overlap: 88.18%
Tensor-likes are not close!
Mismatched elements: 10938039 / 16864896 (64.9%)
Greatest absolute difference: 20.5 at index (0, 78, 16) (up to 0.01 allowed)
Greatest relative difference: 18743296.0 at index (0, 76, 52622) (up to 0.1 allowed)
Expand
The differences are orders of magnitude larger compared to the proposed solutions:
- RMSE: 2.17 vs ~0.08 (27× worse)
- KL Divergence: 27.19 vs ~0.04-0.09 (300-700× worse)
- Top-1 Overlap: 91.89% vs 98-99%
- Mismatched Elements: 64.9% vs 8-13%
This stark contrast demonstrates why achieving training-inference consistency is crucial. The context mismatch in VeRL’s current implementation leads to significant distribution shifts that could severely impact model performance during deployment. All three proposed solutions successfully eliminate this mismatch while maintaining >98% accuracy alignment with the reference implementation.
Next Steps
Having verified the feasibility of these solutions, Part 2 will provide comprehensive benchmarks across multiple dimensions:
- Performance Analysis: Throughput and latency comparisons across varying sequence lengths and batch sizes
- Numerical Accuracy: Statistical analysis of differences across diverse multi-turn datasets
- Memory Efficiency: Peak memory usage and allocation patterns for each approach
- Scalability: How each solution performs with increasing conversation turns and model sizes
These benchmarks will help determine the optimal approach for different use cases in agent reinforcement learning scenarios.